Big Data
The V's of big data
- Velocity
- Increasingly, businesses have stringent requirements from the time data is generated to the time actionable insights are delivered to the users. Therefore, data needs to be collected, stored, processed, and analyzed within relatively short windows, ranging from daily to real time
- Volume
- ranges from terabytes (TB) to petabytes (PB) of data
- Variety
- includes data from a wide range of sources and formats, such as web logs, social media interactions, ecommerce and online transactions, financial transactions, and so on
- Veracity
- the “truth” or accuracy of data and information assets, which often determines executive-level confidence
- Data Veracity is important not only big data but all kinds of data
- Value
- the value from the perspective of business
Tools
Spark
Spark is an open-source distributed computing system designed for big data processing and analytics.
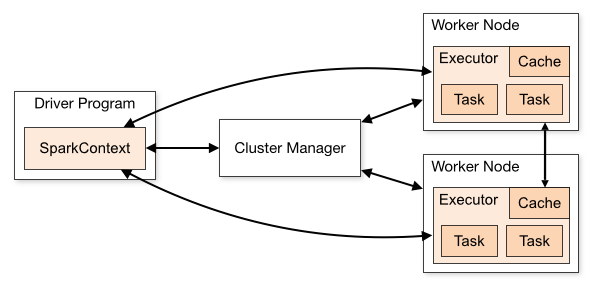
- Resilient Distributed Datasets (RDDs) - the data structure in spark
- Immutable: RDDs are read-only and cannot be modified once created. This immutability ensures consistency and simplifies the data processing model.
- Resilient: RDDs are resilient to failures. They achieve fault tolerance by keeping track of the lineage of transformations applied to the base data. In case of a node failure, RDDs can be reconstructed by re-executing the transformations.
- Distributed: RDDs are distributed across a cluster of machines, enabling parallel processing. The data in an RDD is partitioned into smaller chunks that can be processed independently on different nodes.
- Lazily evaluated: RDDs support lazy evaluation, meaning that transformations on RDDs are not executed immediately. Instead, they are recorded as a sequence of operations that define the RDD's lineage.